트라이(Trie)
dgPassFrontmatter: true
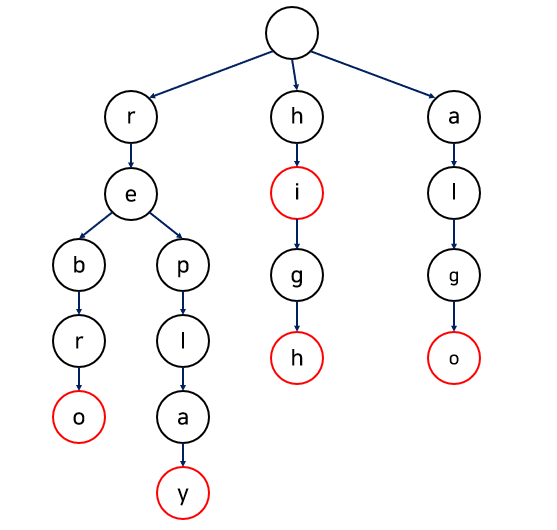
문자를 저장하고 효율적으로 탐색하기 위한 트리(Tree) 형태의 자료구조
위의 예시는 문자열 집합 {"rebro", "replay", "hi" , "high", "algo"} 를 트라이로 구현한 것이다. 빨간색으로 나타낸 노드는 문자열의 끝을 의미한다
자동완성 기능, 사전 검색 등 문자열을 탐색하는 데 특화되어있다
자연어 처리 분야에서 문자열 탐색을 위한 자료구조로 쓰이고 있으며, 검색을 뜻하는 Retrieval의 중간 음절을 따와 Trie라고 부른다
특징
루트 노드는 특정 문자를 의미하지 않고, 자식 노드만 가지고 있다(=루트 노드는 빈 문자와 연관)
자식 노드는 Map<Key, Value> 형태로 가지고 있다
루트 노드를 제외한 노드의 자손들은 해당 노드와 공통 접두어를 가지고 있다
사용
트라이는 주로 문자열 탐색, 자동 검색 완성 등에 사용된다
예를 들어 'N'을 입력하면 사전에 N 다음 나올 수 있는 글자가 무엇인지 들어있으므로, 이를 바탕으로 검색하려는 문자열이 존재하는지를 확인할 수 있다
장점
힙(Heap)과 같은 자료구조에서 원소를 찾는 데는 O(logN)의 시간이 걸린다
이를 문자열에 적용하면 문자열을 비교하기 위해서는 문자열의 길이만큼 시간이 걸리기 때문에 원하는 문자열을 찾기 위해서는 O(MlogN)의 시간이 소요된다(M:문자열 길이, N: 문자열 개수)
이러한 문제를 해결하기 위한 문자열 특화 자료구조가 트라이이다
트라이에서 문자열을 탐색할 때는 다음 글자에 해당하는 노드가 연결되어 있는지를 확인하며, 문자열의 끝에 도달했을 때 해당 노드에서 끝나는 문자열(빨간 노드)이 있다면 찾고자 하는 문자열이 집합에 포함되어 있는 것이다
이러한 구조 때문에 문자열의 길이만큼인 O(M) 만에 탐색이 가능하며, 문자열 추가도 마찬가지의 시간이 걸린다
단점
트라이의 공간복잡도가 크다. 즉, 필요한 메모리의 크기가 너무 크다는 점이다
트라이에 필요한 총메모리는 O(포인터 크기 * 포인터 배열 개수 * 총 노드의 개수)가 된다
그렇기에 1000자리 문자열이 1000개만 들어온다고 하더라도 100만 개의 노드가 필요하고, 포인터의 크기가 8byte라고 하면 약 200MB의 메모리가 필요하게 된다
따라서 이 단점을 해결하기 위해 map이나 vector를 이용해 필요한 노드만 메모리를 할당하는 방식을 이용하기도 한다
구현
파이썬, 자바에서는 클래스를 구현해 트라이 자료구조로 활용할 수 있다
Python
class Node(object):
def __init__(self, key, has_end=False):
self.key = key
self.is_terminal = is_terminal
self.children = dict()
트라이 클래스는 3개의 속성을 갖는다
- key : 해당 노드를 찾기 위한 key이다
- is_terminal : 해당 노드가 단어의 마지막인지를 확인하는 boolean 타입의 속성이다. 또는 재탐색이 필요없도록, 전체 문자열을 저장하는 속성으로 구성해도 좋다(self.data)
- children : 다음 글자로 어떤 것이 저장되어 있는지를 확인할 수 있는 속성이다.
class Node(object):
def __init__(self, key, data=None):
self.key = key
self.data = data
self.children = dict()
class Trie:
def __init__(self):
self.head = Node(None)
def insert(self, string):
current_node = self.head
for char in string:
if char not in current_node.children:
# 새로운 노드 추가
current_node.children[char] = Node(char)
current_node = current_node.children[char]
current_node.data = string
def search(self, string):
current_node = self.head
for char in string:
if char not in current_node.children:
return False
# 현재 노드 갱신
current_node = current_node.children[char]
if current_node.data:
return True
return False
def starts_with(self, prefix):
current_node = self.head
words = []
for p in prefix:
if p not in current_node.children:
return False
current_node = current_node.children[p]
current_node = [current_node]
next_node = []
while True:
for node in current_node:
if node.data:
words.append(node.data)
next_node.extend(list(node.children.values()))
if len(next_node) != 0:
current_node = next_node
next_node = []
else:
break
return words
Java
public class Trie {
Boolean is_terminal;
HashMap<Character, Trie> childNodes = new HashMap<>();
public Trie() {
is_terminal = false;
}
Boolean isLastNode() {
return is_terminal;
}
void setLastNode(Boolean isLastChar) {
is_terminal = isLastChar;
}
void insert(String word) {
Trie trie = this;
for (int i = 0; i < word.length(); i++) {
trie = trie.childNodes.computeIfAbsent(word.charAt(i), c -> new Trie());
}
trie.setLastNode(true);
}
boolean contains(String word) {
Trie thisNode = this;
for (int i = 0; i < word.length(); i++) {
if (thisNode.isLastNode())
return false;
thisNode = thisNode.childNodes.get(word.charAt(i));
if (thisNode == null)
return false;
}
return true;
}
}